1. 네트워크층의 프로토콜은 전송층에게 패킷화 서비스를 제공하는 것이 필요한가? 왜 전송층은 세그먼트를 데이터그램으로 캡슐화하지 않고 전송할 수 없는지 설명하시오.
네트워크층의 프로토콜은 패킷화 서비스를 제공한다. 이는 전송층에서 받은 세그먼트를 적절한 크기로 분할하고, 각각의 패킷에 적절한 헤더 정보를 추가하여 전송할 수 있는 크기의 데이터그램으로 만드는 것이다.
전송층에서는 패킷화 서비스를 제공하지 않는다. 왜냐하면 전송할 데이터의 크기가 네트워크층에서 지원하는 패킷 크기보다 크거나, 패킷화를 하지 않고 전송하는 것이 더 효율적이기 때문이다. 예를들면, TCP에서는 세그먼트의 크기를 동적으로 조정하여 패킷화를 하지 않고도 전송할 수 있는 크기로 분할하는 기능을 제공한다. 따라서 전송층에서는 패킷화 서비스를 제공하지 않아도 된다.
2. 라우팅이 왜 네트워크층의 책임인가? 전송층이나 데이터 링크층에서 라우팅할 수 없는 이유는 무엇인지 설명하시오.
라우팅은 패킷을 목적지까지 안전하고 효율적으로 전달하기 위해 경로를 선택하는 과정이다.
전송층이나 데이터 링크층에서 라우팅을 할 수 없는 이유는 해당 계층에서는 목적지까지의 경로 선택과 같은 라우팅 관련 정보가 없기 때문이다. 예를 들어, 데이터 링크층은 물리적인 매체를 통해 다른 노드와 통신을 하기 때문에, 해당 매체로 건너갈 수 있는 다음 노드가 알 수 있다. 즉, 데이터 링크층에서는 라우팅을 위해 경로를 선택하거나 라우팅 테이블을 가지고 있지 않는다.
결과적으로 라우팅은 네트워크층에서 이루어져야 한다.
3. 발신지에서 목적지까지 패킷의 라우팅 처리 과정과 각 라우터에서 패킷의 전달 과정을 구분해서 설명하시오.
발신지에서 목적지까지 패킷의 라우팅 처리 과정
1. 발신지 호스트에서 IP 패킷을 생성
2. 발신지 호스트에서 패킷의 목적지 IP 주소를 확인하고, 목적지가 다른 네트워크에 있는 경우, 목적지 IP 주소의 네트워크 ID를 통해 라우팅 테이블을 검색
3. 발신지 호스트에서 라우팅 테이블에 가장 적합한 라우터의 IP 주소를 찾아 해당 라우터로 패킷을 전송
4. 발신지 호스트에서 패킷의 출발지 IP 주소와 목적지 IP 주소를 포함하는 헤더를 추가
5. 발신지 호스트에서 패킷을 전송
6. 라우터는 수신한 패킷의 목적지 IP 주소를 검사한 후 패킷이 수신한 인터페이스를 통해 전달될 수 있는 경우 패킷을 해당 인터페이스 혹은 다음 라우터로 패킷을 전달
7. 목적지 호스트에서 IP 패킷을 수신한 후 패킷의 데이터를 추출하여 응용 프로그램으로 전달
패킷 생성(발신지) -> 목적지 검색(발신지) -> 라우터로 패킷 전송(발신지) -> 출발지 IP & 목적지 IP 헤더 추가(발신지) -> 패킷 전송 (발신지) -> 검사 및 전달(라우터) -> 수신 & 추출 (목적지)
각 라우터에서 패킷의 전달 과정
1. 패킷이 라우터로 도착
2. 라우터는 수신한 패킷의 목적지 IP 주소를 검사
3. 패킷의 목적지 IP 주소가 라우터가 직접 연결된 네트워크에 있는 경우, 라우터는 해당 인터페이스로 패킷을 전달
4. 패킷의 목적지 IP 주소가 다른 네트워크인 경우, 라우터는 라우팅 테이블을 검색하여 다음 라우터로 패킷을 전달
5. 라우터는 전달할 패킷의 TTL 값을 감소시킴
6. 라우터는 패킷의 출발지 IP 주소를 자신의 IP 주소로 바꾸고, 패킷을 다음 라우터로 전달
7. 패킷이 목적지에 도착할 때까지 3-6 단계를 반복
도착(라우터) -> 목적지 IP 검사(라우터) -> 직접 연결된 경우 인터페이스로 전달 / 다른 네트워크인 경우 라우팅 테이블 검색 후 전달 -> TTL 값 감소 -> 출발지 IP 수정 후 다음 라우터로 전달(라우터) -> 도착 까지 반복
4. 교환에 대한 다음 방법에서 포워딩 결정 시에 만들어지는 패킷의 정보 조각은 무엇인지 설명하시오.
1) 데이터그램 방식
패킷의 정보 조각은 목적지 IP 주소와 출발지 IP 주소 등을 포함한 IP 헤더
2) 가상 회선 방식
VCI와 VPI로 구성된 VC 식별자
VCI(Virtual Channel Identifier)는 가상 회선 내에서 연결된 두 호스트 사이에서 패킷을 식별하는데 사용됨
VPI(Virtual Path Identifier)는 물리적인 네트워크에서 가상 회선을 식별하는데 사용된다.
5. 연결형 서비스에서 레이블이 8비트일 때, 얼마나 많은 가상 회선을 동시에 설정할 수 있는가?
8비트로 표현되는 레이블은 2^8=256개의 서로 다른 값을 가질 수 있다.
연결형 서비스에서 가상 회선 하나를 설정하기 위해서는 레이블이 하나 필요하다.
6. 가상 회선 접근 방법에서 교환을 위한 세 단계를 기술하시오.

1. 가상 회선 설정(Virtual Circuit Setup) : 송신 호스트에서 수신 호스트로 데이터를 보낼 때, 먼저 송신 호스트는 가상 회선을 설정하기 위해 라우팅 정보를 수신 호스트로부터 얻는다. 이때 라우팅 정보는 VC 식별자, 입구 포트 번호, 출구 포트 번호, 전송 지연 등의 정보를 포함한다.
2. 데이터 전송(Data Transfer) : 가상 회선이 설정되면, 송신 호스트는 데이터를 전송할 수 있다. 이때, 송신 호스트에서는 데이터를 패킷(Pacekt)단위로 나누고, 패킷 헤더에 VC 식별자를 추가한다. 또한, 패킷 헤더에는 수신 호스트의 주소도 포함되어 있다.
3. 가상 회선 해제(Cirtual Circuit Teardown:) : 데이터 전송이 끝나면 송신 호스트는 가상 회선을 해제한다. 이때, 송신 호스트에서는 라우팅 정보를 수신호스트로 보내고, 수신 호스트에서는 이를 수신하여 가상 회선을 삭제한다.
가상 회선 설정 -> 데이터 전송 -> 회선 해제
7. TCP/IP의 네트워크층에서 다음과 같은 서비스를 제공해야 하는가? 만약 아니라면 왜 그런지 설명하시오.
1) 흐름 제어
2) 오류 제어
3) 혼잡 제어
TCP/IP의 네트워크층에서는 1)흐름 제어, 3)혼잡 제어 서비스는 제공한다. 하지만 2)오류 제어 서비스는 제공하지 않는다.
흐름 제어는 수신자가 허용할 수 있을 만큼만의 데이터만 보내도록 조절해 준다. 만약 송신자 측의 사우이 계층에서 수신자 측의 상위 계층이 처리할 수 있는 양보다 더 많은 데이터를 전송하는 경우 수신측에서는 이 데이터를 감당할 수 없게 된다. 데이터의 흐름을 제어하기 위해 수신자는 자신이 데이터를 감당할 수 없는 것을 알리기 위한 피드백을 전송한다.
오류 제어는 네트워크 층에서 구현될 수도 있지만, 인터넷의 네트워크층 설계자들은 네트워크층에 의해 전달되는 데이터에 대해 오류 제어를 고려하지 않는다. 이 같은 결정의 이유는 각 라우터에서 패킷이 단편화될 때마다 네트워크층에서 오류를 검사하는 것이 비효율적이기 때문이다.
혼잡은 네트워크층에서 인터넷의 영역 속에 너무 많은 데이터그램이 존재 하는 경우, 송신자가 보낸 데이터그램이 네트워크나 라우터의 처리 성능을 넘어서는 경우 발생한다. 혼잡이 지속되면 때떄로 시스템이 붕괴되고 데이터그램이 하나도 전달되지 못하는 상황에 이를 수도 있다.
8. 패킷 교환망에서 지연의 네 가지 유형을 나열하시오.
1) 전송 지연(transmission delay)
Delay_tr = (packet length) / (transmission rate)
2) 전파 지연(propagation delay)
Delay_pg = (distance) / (propagation speed)
3) 처리 지연(processing delay)
Delay_pr = 라우터나 목적지 호스트에서 패킷을 처리하는데 걸리는 시간
4) 대기 지연(queuing delay)
Delay_qu = 패킷이 라우터에 있는 입력과 출력 큐에서 기다리는 시간
‼️) 전체 지연
Total Delay = (n+1)(delay_tr + delay_pg + delay_pr) + (n)(delay_qu)
9. 그림에서 R1과 R2 사이의 링크가 170kbps로 업그레이드되고, 발신지 호스트와 R1 사이의 링크가 140kpbs로 다운그레이드되었다고 가정하자. 이 변경 후에 발신지와 목적지 사이의 처리율은 어떻게 되는가? 어떤 링크가 지금 병목현상이 있는지 설명하시오.
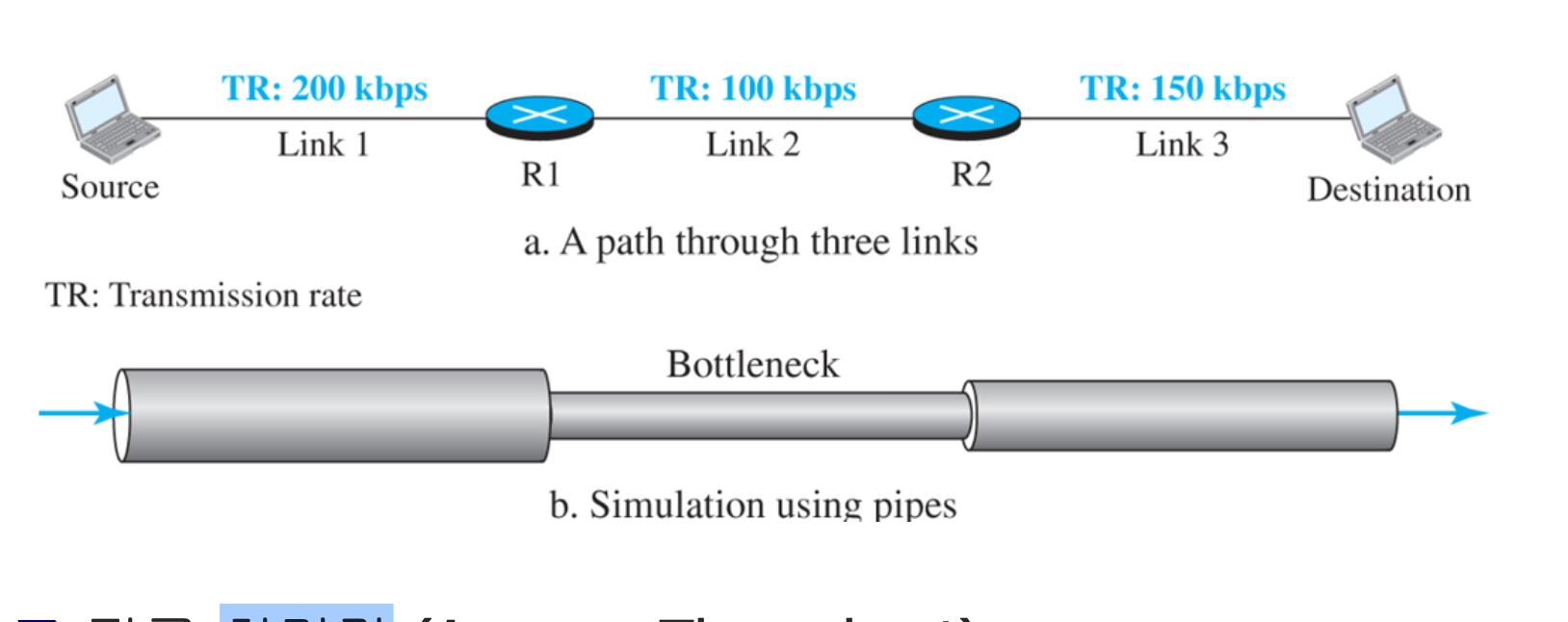
데이터 전송의 병목 현상을 확인하기 위해서는 병목현상을 일으키는 가장 느린 링크를 파악해야 한다.
처리량(throughput) = minimum {TR_1, TR_2, ... , TR_n}
즉, 발신지 호스트와 R1 사이의 링크가 minimum값으로 현재 병목현상을 일으키며, 발신지와 목적지 사이의 처리율은 140kbps이다.
10. 클래스 없는 주소 지겅에서 블록의 첫 번째와 마지막 주소를 알고 있다. 접두사 길이를 찾을 수 있는가? 만약 있다면 과정을 보이시오.
찾을 수 있다.
과정)
A) 블록의 첫 번째 주소와 마지막 주소를 이진수로 변환한다.
B) 첫 번째 주소와 마지막 주소를 비교하여 가장 높은 자리수부터 차이가 나는 위치를 찾는다.
C) 해당 위치의 자리수를 접두사 길이로 사용한다.
Exemple) 첫번째 주소 192.168.1.0 / 두번째 주소 192.168.1.255
A) 이진수로 변환
첫번째 주소 192.168.1.0 -> 11000000.10101000.00000001.00000000
두번째 주소 192.168.1.255 -> 11000000.10101000.00000001.11111111
B) 가장 높은 자리수 차이 -> 마지막 바이트
C) 2^8 = 256개, 0~255
11. 클래스 없는 주소 지정에서 블록의 첫 번째 주소와 주소의 수를 알고 있다. 접두사 길이를 찾을 수 있는가? 만약 있다면 그 과정을 보이시오.
찾을 수 있다.
주소의 수를 이용하여 블록의 크기를 구한 후, 블록의 크기의 비트 수를 이용하여 접두사의 길이를 계산할 수 있다.
과정)
A) 블록의 크기 계산 : 블록의 크기 = (마지막 주소 - 첫 번째 주소) + 1
B) 블록 크기의 비트 수 계산
C) 접두사 길이 계산
Exemple) 첫번째 주소 192.168.1.63 / 주소의 수 256
256 = 2^8
접두사의 길이는 8비트이므로 /24 서브넷 마스크를 사용하는 것과 같다.
12. 클래스 없는 주소 지정에서 2개의 서로 다른 블록이 동일한 접두사 길이를 가질 수 있는가?
가능하다.
예를 들면 10.0.0.0/24 & 10.1.0.0/24는 둘 다 /24 접두사 길이를 가지지만 서로 다른 블록이다.
13. IPv4 패킷의 헤더 길이 필드가 5보다 적은 값을 가질 수 있는지 설명하시오. 언제 정확하게 5가 되는가?
IPv4 패킷의 헤더 길이 필드는 4바이트(32비트) 단위로 표현되며, 최소값은 5이고, 최대값은 15이다.
이 값은 IPv4 패킷의 헤더의 길이를 32비트 워드 단위로 표현한 것이며, 5는 최소값으로 헤더 길이가 20바이트일 때 해당한다.
따라서 IPv4패킷의 헤더 길이 필드가 5보다 작은 값을 가질 수는 없다.
또한 헤더에 옵션이 추가될 때마다 32비트 워드 단위로 증가하므로, 28바이트 길이의 헤더가 3바이트 옵션이 추가되면 헤더 길이의 값은 7이 된다. (28 + 3) * 4 = 124, 2^7 = 128
14. 호스트가 100개의 데이터그램을 다른 호스트에게 전송했다. 만약 첫 번째 데이터그램의 식별 번호가 1,024이면 마지막 식별 번호는 무엇인가?
IPv4의 식별자 필드는 16비트(2바이트) 크기이므로, 최대 2^16-1 = 65,535까지 값을 가질 수 있다.
데이터그램이 100개 이므로, 마지막 데이터그램의 식별 번호는 1,204 + 99 = 1,123 이다.
15. 오프셋 값이 100인 IP 단편이 도착했다. 원래 이 단편에 있는 데이터 이전에 발신지에서 전송한 데이터는 몇 바이트인지 설명하시오.
IP 단편화는 원래 데이터그램의 일부인데, 원래 데이터그램은 IP 헤더와 함께 전송되기 때문에 오프셋 값이 100이라는 것은 이미 100*8(바이트) = 800 바이트만큼의 데이터가 전송되었음을 의미한다.
따라서 발신지에서 전송한 데이터 이전의 크기는 800바이트이다.
16. TCP/IP 프로토콜 그룹의 네트워크층에서 IPv4 프로토콜을 돕기 위한 세 가지 보조 프로토콜을 기술하시오.
a) ARP(Address Resolution Protocol): ARP는 IP 주소를 물리적인 MAC 주소로 변환하기 위한 프로토콜이다. ARP는 네트워크 상에서 다른 호스트의 MAC 주소를 검색하여, 데이터 링크 계층에서 패킷을 전송하기 위해 필요한 정보를 제공한다.
b) ICMP(Internet Control Message Protocol) : ICMP는 네트워크 상에서 오류 메시지와 제어 메시지를 전송하기 위한 프로토콜이다. ICMP 메시지는 네트워크에서 발생하는 문제를 식별하고, 네트워크 관리자가 문제를 해결하기 위한 정보를 제공한다.
c) IGMP(Internet Group Management Protocol) : IGMP는 멀티캐스트 그룹 관리를 위한 프로토콜이다. IGMP는 호트스와 라우터 간에 멀티캐스트 그룹 멤버십 정보를 교환하여, 멀티캐스트 트래픽을 효율적으로 전송한다. 여기서 멀티캐스트란, 하나의 송신자가 네트워크에 있는 여러 수신자에게 동시에 데이터를 전송하는 방법이다.
17. IPv4 데이터그램에서, 헤더 길이(HLEN) 필드 값이 (6)_16이다. 얼마나 많은 옵션 바이트가 패킷에 추가되었는지 설명하시오.
IPv4 헤더 길이(HLEN)필드 값은 4바이트 단위로 헤더 길이를 표시한다. 헤더 길이 필드 값이 (6)_16이라면, 헤더 길이는 6*4=24(바이트)가 된다. 이 중에서 20바이트는 고정 헤더이므로 4바이트 옵션 바이트가 패킷에 추가되었다.
18. 다음 주어진 값들이 데이터그램의 TTL 값이라고 할 때 어떤 의미인지 설명하시오.
1) 23
2) 0
3) 1
4) 301
TTL(Time to Live) 값은 IP 데이터그램이 무한정 라우팅되는 것을 방지하기 위해 사용되는 8비트(1바이트) 필드이다.
1) 23 : 데이터 그램이 라우터를 거칠 때마다 TTL 값이 1씩 감소하므로, 이 데이터그램은 23번의 라우터 통과가 허용된다.
2) 0 : TTL 값이 0이 된 데이터그램은 라우터에서 폐기된다. 무한히 라우팅되는것을 방지하기 위함이다.
3) 1 : 이 데이터그램은 목적지까지 단 한 번만 전달될 것이다. 따라서 TTL 값이 1인 데이터그램은 마지막 목적지까지 직접 전송되어야한다.
4) 301 : TTL의 최대값은 (2^8 = 256개, 0~255), 255이므로, 301은 올바른 TTL값이 아니므로 라우터에서 폐기된다.
19. 네트워크층의 프로토콜 필드와 전송층의 포트 번호를 비교해서 설명하시오. 이들의 공통적인 목적은 무엇인가? 왜 프로토콜 필드는 하나인데 포트 번호 필드는 2개가 필요한가? 왜 프로토콜 필드의 크기는 각 포트 번호 크기의 절반이가?
네트워크층의 프로토콜 필드는 IP 패킷이 전달되는 대상 네트워크층 프로토콜을 식별하는 데 사용된다.
반면, 전송층의 포트 번호는 수신 호스트의 어떤 응용 프로그램이 데이터를 처리할지 결정하는데 사용된다. 즉, 특정한 응용 프로토콜을 식별하는데 사용되며, 전송 계층의 포트 번호는 네트워크 계층의 프로토콜 필드에서 전달된 패킷이 어떤 응용 프로그램으로 전달될지 결정한다.
프로토콜 필드는 전송되는 데이터그램의 목적지 네트워크 계층 프로토콜을 식별하기만 되기 때문에 하나만 있으면 충분하다.
하지만, 전송층에서 포트 번호는 응용 프로그램을 구분하기 위해 필요하기 떄문에 발신 호스트는 전송 계층에게 데이터그램을 어떤 응용프로그램을 전달할지 지시하기 위한 송신 포트 번호, 목적지 호스트는 데이터그램을 어떤 응용프로그램에서 처리할지를 식별하기 위한 수신 포트 번호로 총 2개가 필요하다.
20. 데이터그램에서 어떤 필드가 모든 단편이 원래의 데이터그램에 속한 것이라는 것을 나타내는가?
데이터그램의 Flags 필드가 모든 단편이 원래 데이터그램에 속한 것인지를 나타낸다. 1로 설정되면 다른 단편들과 함께 데이터그램의 일부임을 나타내며, 0으로 설정된 경우 마지막 단편임을 나타낸다.
21. 다음에 주어진 각각이 데이터그램의 옵셋 필드 값이라고 할 때에 그 의미를 설명하시오.
1) 8
2) 31
3) 73
4) 56
IPv4 데이터그램에서, 오프셋(Offset)필드 값은 단편화된 데이터그램의 원래 데이터그램에서의 위치를 나타낸다.
8바이트 단위로 증가하며, 데이터그램의 첫 번째 바이트가 원래 데이터그램의 몇 번째 바이트인지 나타낸다.
1) 8 : 해당 단편의 첫 번째 바이트는 8 * 8 = 64번째 바이트에 위치한다.
2) 31 : 31 * 8 = 248번째 바이트에 위치
3) 73 : 73 * 8 = 584번째 바이트에 위치
4) 56 : 56 * 8 = 448번째 바이트에 위치
22. 목적지 컴퓨터가 발신지로부터 여러 패킷을 수신하다고 가정하자. 한 데이터그램에 속한 단편들이 다른 데이터그램의 단편들과 섞이지 않았다고 어떻게 회신할 수 있는지 설명하시오.
IPv4 데이터그램의 헤더에는 식별자 필드가 있다.
이 필드는 해당 데이터그램을 유일하게 식별할 수 있는 값을 가지고 있다. 그리고 IP 단편화에서, 데이터그램의 모든 단편들은 동일한 식별자를 가지고 있다.
따라서, 목적지는 동일한 식별자를 가진 단편들을 하나의 데이터그램으로 결합할 수 있다. 또한, 데이터그램의 단편화에서 각 단편에는 오프셋 필드가 있다. 이 필드는 해당 단편이 전체 데이터그램에서 어느 위치에 있는지를 나타낸다.
이러한 정보들을 바탕으로 모든 단편을 올바른 순서대로 결합하여 원래의 데이터그램으로 복원할 수 있다.
23. 인터넷이 ICMPv4 메시지를 전달하는 IP 데이터그램의 오류를 보고하는 보고 메시지를 생성하지 않는 이유는 무엇인지 설명하시오.
인터넷에서 ICMPv4 메시지를 전달하는 IP 데이터그램이 오류를 보고하면, 오류 메시지에 대한 응답 메시지가 발생한다.
이 응답 메시지는 지나온 경로를 거꾸로 따라 이동하며 경로에 있는 모든 라우터에서 처리된다. 이는 경로를 많이 따라 이동하기 때문에 인터넷의 대역폭을 차지하고, 라우터의 부담을 늘리며, 과도하게 발생할 경우 네트워크 성능에 영향을 미친다.
따라서, 일반적으로 ICMPv4 메시지를 전달하는 IP 데이터그램의 오류를 보고 하지 않고 데이터그램을 버리거나 분실된 데이터그램을 추적하는데 도움을 주는 다른 방법을 사용한다.
24. 라우터에 의해 보고된 ICMPv4 메시지를 전달하는 데이터그램의 발신지와 목적지 IP 주소는 무엇인지 설명하시오.
데이터그램의 발신지 IP 주소 = 해당 라우터의 IP 주소
데이터그램의 목적지 IP 주소 = ICMPv4 메시지를 발생시킨 호스트의 IP 주소
25. 왜 등록 요청과 응답이 IP 데이터그램에 직접 캡슐화되지 않는지 이유를 설명하시오. 여기서 UDP 사용자 데이터그램이 왜 필요한지 설명하시오.
오류 상황시, ICMP가 IP 라우터에서 생성되고 전송되기 때문에 ICMP 메시지는 IP 데이터그램 내에 포함되지만, 직접 캡슐화되지 않는다.
UDP(User Datagram Protocol) 사용자 데이터그램은 등록 요청과 응답을 전송하는데 사용된다. 이는 ICMP 메시지보다 상위 수준의 프로토콜이며, UDP는 오류 검출 기능만 가지고 있기 때문에 등록 요청과 응답이 UDP 데이터그램에 캡슐화되어 전송된다.
이를 통해 ICMP 메시지와 같은 하위 수준 프로토콜에서 발생한 오류를 감지하고, 상위 수준에서 처리할 수 있다.
'컴퓨터네트워크' 카테고리의 다른 글
| 데이터 통신과 네트워킹 6th by foruzan, 7장 기본 연습문제 (0) | 2023.04.14 |
|---|---|
| 네트워크층: 데이터 전송 - IP 패킷의 포워딩 (0) | 2023.04.14 |
| 네트워크층: 데이터전송 - 이동 IP (0) | 2023.04.14 |
| 네트워크층: 데이터전송 - ICMPv4 (0) | 2023.04.13 |
| 네트워크층: 데이터전송 - 데이터그램(Datagram) (0) | 2023.04.13 |



