TensorFlow : 딥러닝 알고리즘을 수행하는 라이브러리로 TensorFlow2.0 부터는 직관적이고 쉽게 배울 수 있는 Keras를 High-Level API로 공식지원함으로서, 이러한 영향력이 더 커질 것으로 예상된다.
이 외의 라이브리리로는 PyTorch, Caffe, MXNext, CNTK 등이 있다.

TensorFlow 2.x
특징:
1. 즉시 실행 모드(Eager Xecution) : 코드의 직관성을 높여주고, Session 생성 없이 즉시 실행할 수 있다.
2. 사용자 친화적 : Keras만을 High-Level API로 공식 지원함
3. numpy() 메서드를 사용하면 numpy값을 리턴해 줌
장점:
1. 계산 그래프와 세션을 생성하지 않고 즉기 실행 가능한 Eager Execution 적용
2. High-Level API로서 Keras만을 제공

TensorFlow 1.x에서는 계산 그래프를 선언하고, 세션을 통해 Tensor를 주고 받으며 계산하는 구조였으나, TensorFlow 2.x에서는 자동으로 Eager Execution이 적용되기 때문에 그래프와 세션을 만들지 않아도 Tensor 값을 계산하고 numpy() 함수를 이용하면 파이썬의 numpy 타입으로 변환할 수 있다.
상수 만들기 tf.constant(...)
1.x 버전
import tensorflow as tf
a = tf.constant(1.0)
b = tf.constant(2.0)
c = a + b
print(c) -> 이와 같이 1.x 버전은 만들지 않고 print와 같은 명령문을 실행하면, 지정된 값이 아닌 현재 정의되어 있는 노드의 상태가 출력된다.
with tf.Session() as sess:
print(sess.run(c)) -> session을 만든 후에 연산 실행
2.x 버전
import tensorflow as tf
a = tf.constant(1.0)
b = tf.constant(2.0)
c = a + b
print(c.numpy()) -> Eager Execution으로 세션을 생성하지 않고, 오퍼레이션을 실행하는 순간 연산이 수행되기 때문에 오퍼 레이션 실행 결과를 numpy 값으로 즉시 알 수 있다. 즉, 모든 코드는 쓰여진 순서에 따라 즉시 실행되는 Eager Execution으로 결과를 바로 알 수 있음
변수 선언 tf.Variable
TensorFlow 2.x 버전 에서는 tf.Variable 값을 초기화 함을 위해 세션 내에서 tf.global_variable_initializer() 과정이 필요없으며, 변수를 정의함과 동시에 초기 값이 할당됨(Eager Execution)
1.5 버전
import tensorflow as tf
w = tf.Variable(tf.random_normal([1]) # 가우시안 분포
# Session 생성
# tf.Varialbe(...) 초기화 해주는 코드 실행 후 연산 실행
with tf.Sessiont() as sess:
# 변수 노드 값 초기화
sess.run(tf.global_variables_initializer())
for step in range(2):
w = w + 1.0
print( "w = ", sess.run(w))
tf.placeholder(...) -> 2.x 버전에서는 삭제, 함수를 실행하여 결과를 업디기위해서는 tf.placeholder()에 입력 값을 주어야 함
2.x 버전
w = tf.Variable(tf.random.normal([1])
# Session 생성 없이 즉시 실행
# numpy() 메서드를 사용하면 numpy값을 리턴해줌
for step in range(2):
w = w + (1.0) -> 변수 w 초기화 없이 즉시 실행
print(w.numpy())
Keras
특징:
1. User Friendliness : 직관적인 API, 일반 신경망(ANN), CNN, RNN 모델 또는 다양한 조합의 딥러닝 모델을 손 쉽게 구축 가능
2. Modularity : Keras에서 제공하는 모듈은 독립적으로 설정 가능 -> 새로운 조합으로 새로운 딥러닝 모델 구축 가능
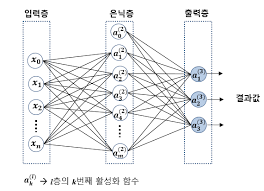
- 모델은 각 층을 포함하고 있는 신경망 자체를 나타냄,
모델의 기본 단위는 층(layer)이며, 이러한 층을 레고처럼 순차적으로 쌓기만 하면 다양한 조합의 모델을 구축할 수 있음
model = Sequential() # 모델 생성
model.compile # 손실함수 지정, Optimizer 지정
model.fit(...) # 학습진행 (input, feed forward, y, update)
Keras 개발 과정
데이터 생성 -> 모델 구축 -> 모델 컴파일 -> 모델 학습 -> 모델 평가 및 예측 -> 모델 저장
model = Sequential() -> model.compile(...) -> model.fit(...) -> model.evaluate(...) / model.predict(...) -> model.save(...)
데이터 생성
1. train data : 학습에 사용되는 Data, 가중치와 바이어스 최적화에 사용
2. Validation data : 1 epoch 마다 overfitting을 확인하기 위해 사용
3. test data : 학습 후 정확도 평가 및 결과 예측을 위해 사용되는 Data
모델 구축
model = Sequential()
model.add(Flatten(input_shape(1,))
model.add(Dense(2, activation = 'sigmoid')
model.add(Dense(1, activation = 'sigmoid')
model.add(Dense(2, activation = 'sigmoid', input_shape(1,))Flatten은 입력으로 들어오는 다차원 데이터를 1차원으로 정렬하귀 위해 사용하는 레이어이며 입력 데이터(차원)의 수를 input_shape = (1,)과 같이 기술함
Dense는 각 층의 입력과 출력 사이에 있는 모든 노드가 서로 연결되어 있는 완전 연결 층(FC)를 나타냄, 첫 번째 인자는 촐력 노드 수를 나타냄
모델 컴파일
구축된 모델을 기계가 이해할 수 있도록 컴파일 해야 하며, 최적화 방법(알고리즘), 오차함수, 학습 과정 중에 모니터링할 지도(metric)를 나타낼 수 있음
일반적으로 model.compile(...) 후에는 model.summary()를 통해서 구축 모델 확인
ex1)
model.compile(optimizer = SGD(learning_rage = 0.1, loss = 'mse', metrics = ['accuracy'])
최적화 알고리즘 SGD, 학습율 0.1, 오차함수 mse, 메트릭은 accuracy(loss는 기본)
ex2)
model.compile(optimizer = Adam(learning_rage = 1e-4), loss = 'categorical_crossentropy')
최적화 알고리즘 Adam, 학습률 1e-4, 오차함수 categorical_crossentropy
모델 학습
손실 함수 값이 최소가 될 때까지 각층의 가중치와 바이어스를 업데이트 하는 과정
ex1)
model.fit(x_train, t_train, epochs = 10, batch_size=100, verbose = 0, validation_split = 0.2)
# 입력 데이터: x_train, 정답 데이터: t_train, 반복 횟수: epochs, 배치 사이즈(생략가능): batch_size, 학습데이터의 20%를 검증 데이터로 사용: (validation_split = 0.2)verbose : 학습 중 손실 값, 정확도, 진행 상태 등의 출력 형태를 설정함 (0, 1, 2)
검증데이터가 별도로 있다면, validation_split 대신 validation_data 이용하여 지정 가능
모델 평가
학습을 마친 후, test data를 통해서 모델을 평가 하고 임의의 데이터에 대해 예측함
ex1)
model evaludate(x_test, t_test, epchos = 10, batch_size = 100)
# 테스트 데이터, 정답 데이터, 시도 횟수, 배치 사이즈(생략 가능)
ex2)
model.predict (x_input_data, batch,size = 100)
# x_input_data: 예측하고자 하는 데이터
모델 저장
학습이 끝난 (가중치와 바이어스가 최적화된) 신경망 구조를 저장해 놓는다면, 다양한 테스트 데이터에 대해 재 삭습 없이 지속적으로 사용할 수 있음
model.save("model_name.h5")
# 학습이 끝난 모델을 hdf5 파일에 저장함
model = tensorflow.keras.models.load_model("model_name.h5")
# 저장되어 있는 모델 (model_name.hdft)를 불러옴'머신러닝공부' 카테고리의 다른 글
| Logistic Regression - Classfication 요약 정리 (0) | 2022.12.25 |
|---|---|
| Linear Regression 예제 스크립트 (0) | 2022.12.25 |
| 머신러닝의 회귀(Regression)과 손실함수, GDA에 대한 간단정의 (0) | 2022.12.25 |
| Docceptor 머신러닝 강의 학습 후기 (0) | 2022.12.19 |
| 머신러닝공부를 시작하며 (0) | 2022.12.19 |

